
[SQLD]데이터 모델링과 SQL(2)
관계와 조인의 이해
관계 (Relationship)
- 테이블 간의 연결을 의미한다. 두 개의 엔티티 사이의 논리적인 연결, 엔티티와 엔테티가 존재의 형태나 행위로서 서로에게 영향을 주는 관계.
- 일대일 (One-to-One)
- 일대다 (One-to-Many)
- 다대다 (Many-to-Many) - 이 관계는 보통 별도의 연결 테이블을 통해 구현된다.
조인 (Join)
- 조인은 두 개 이상의 테이블을 연결하여 데이터를 검색하는 데 사용되는 방법
- Inner Join - 두 테이블의 교집합 반환
- Outer Join
- Left Outer Join - 왼쪽 테이블의 모든 레코드와, 오른쪽 테이블의 교집합 부를 반환. 일치하는 레코드가 없는 경우 오른쪽 테이블의 값은 NULL로 표시된다.
- Right Outer Join - 오른쪽 테이블의 모든 레코드와 왼쪽 테이블의 교집합 부를 반환.
- Full Outer Join - 두 테이블의 합집합을 반환. 일치하지 않는 레코드는 NULL로 반환.
- Inner Join - 두 테이블의 교집합 반환
계층형 데이터 모델
데이터를 트리 구조로 표현하는 방식으로서 동일한 데이터에서 상하 구조가 있는 것을 말한다.
데이터를 계층적으로 구조화하여 관리하며, 각 계층은 다른 계층과 부모-자식 관계를 갖는다. 즉, 계층형 데이터 모델에서는 한 레코드가 자기 자신에 대한 관계를 가질 수 있다. 이런 관계를
순환관계혹은자기참조관계라고한다.셀프-조인
상호배타적 관계
-
한 요소 또는 그룹이 다른 요소 또는 그룹과 동시에 속할 수 없는 관계
ex) A - 피자 주문 / B - 파스타주문
피자를 주문한 사람은 파스타를 주문할 수 없고, 파스타를 주문한 사람은 피자를 주문할 수 없다면 이 때 피자와 파스타는 상호배타적 관계에 있다고 한다.
모델이 표현하는 트랜잭션의 이해
트랜잭션
- 데이터 베이스의 논리적 연산단위 ex) 은행 계좌 이체
- 시작 : 어떤 일련의 작업을 시작하려고 할 때 트랜잭션도 시작된다.
/ A계좌에서 B계좌로 100달러를 이체하려고한다. - 작업 수행 : 트랜잭션은 하나이상의 작업으로 이루어짐
/ (1) A에서 100달러를 뺀다.
/ (2) B에 100달러를 더한다. - 확인(Commit) : 모든 작업이 성공적으로 수행되었다면 트랜잭션을 완료하기 위해 확인단계로 넘어감.
/ A계좌의 인출과 B계좌의 입금이 성공하면 트랜잭션을 커밋하여 최종 결과를 반영 - 롤백(Rollback) : 중간에 에러가 발생한다면, 트랜잭션을 롤백하여 모든 작업을 취소
/ A계좌의 잔고 부족 등으로 트랜잭션이 실패한다면 모든 작업을 취소하고 첫 상태로 돌아감. - 끝 : 트랜잭션이 커밋되거나 롤백되면 트랜잭션은 종료된다.
/ 모든 작업이 반영되거나, 아무런 영향도 받지 않고 끝난다.
- 시작 : 어떤 일련의 작업을 시작하려고 할 때 트랜잭션도 시작된다.
트랜잭션의 특징 (ACID)
- 원자성 (Atomicity) : 모든 작업이 성공하거나, 실패하는 경우만 존재한다.
- 일관성 (Consistency) : 트랜잭션 후 데이터베이스의 상태는 일관되어야 한다.
- 고립성 (Isolation) : 여러 트랜잭션이 도잇에 실행 될때 각 트랜잭션은 서로 영향을 미치지 않도록 한다.
- 지속성 (Durability) : 성공적으로 완료된 경우 변경 사항은 데이터베이스에 영구반영 되어야한다.
NULL 속성의 이해
- 정해지지 않음 / 데이터베이스에서 특정 필드 또는 칼럼에 값이 없음을 나타내는 특별한 값
- 공백이나 숫자0 과는 다른 의미이다.
Null의 특징
- 미정상태
- 데이터부재
- 값의비교 불가능
집계함수와 Null
- 집계함수는 대부분 Null값을 제외하고 처리되기도 한다. 데이터베이스에서 Null 값이 특별한 상황을 나타내거나 연산에서 불확실한 결과를 가져오기 때문이다.
- SUM - 일반적으로 Null값은 0으로 처리된다. 따라서 Null값을 제외하고 나머지 값들의 합을 계산한다.
- AVG - Null값을 제외하고 나머지 값들의 평균을 계산한다.
- COUNT - 행의 개수를 세는 함수 / 일반적으로 Null값을 제외하고 유효한 값들의 개수를 센다.
단,COUNT(*)의 경우 Null을 포함해서 모든 행의 수를 리턴한다. - MIN/MAX - 최소,최대값 / Null값을 무시하고 나머지 값중에서 최소값과 최대값을 찾는다.
본질식별자와 인조식별자
식별자 : 엔티티내에서 데이터를 구분할 수 있는 구분자
본질식별자 (Natural Key)
- 데이터 엔터티를 식별하는데에 자연스럽게 존재하는 속성이나 조합. 실제 데이터와 밀접한 관련이 있는 속성으로, 엔터티가 갖고 있는 자연스러운 속성을 활용하여 식별자로 사용하는 것
- 데이터베이스에 의미있는 정보를 포함하므로 인간이 읽고 이해하기 쉽고, 데이터 일치성이 높다.
- 데이터 속성의 변화나 형식이 변경이 발생하면 식별자에도 영향이 가며, 복합 본질 식별자의 경우 복잡성이 증가한다.
인조식별자 (Surrogate Key)
- 업무적으로 만들어지지는 않지만, 본질식별자가 복잡한 구성을 가졌을 때 인위적으로 만든 식별자, 주로 시스템이나 데이터베이스 설계 목적으로 생성한다.
- 데이터 일관성이 유지되며, 데이터 변화의 영향이 적으며 본질식별자의 복잡성을 피할 수 있다.
- 사용자의 이해가 어려울 수 있다. 중복되지 않도록 일련번호등을 생성하는데 추가적 관리가 필요하다.
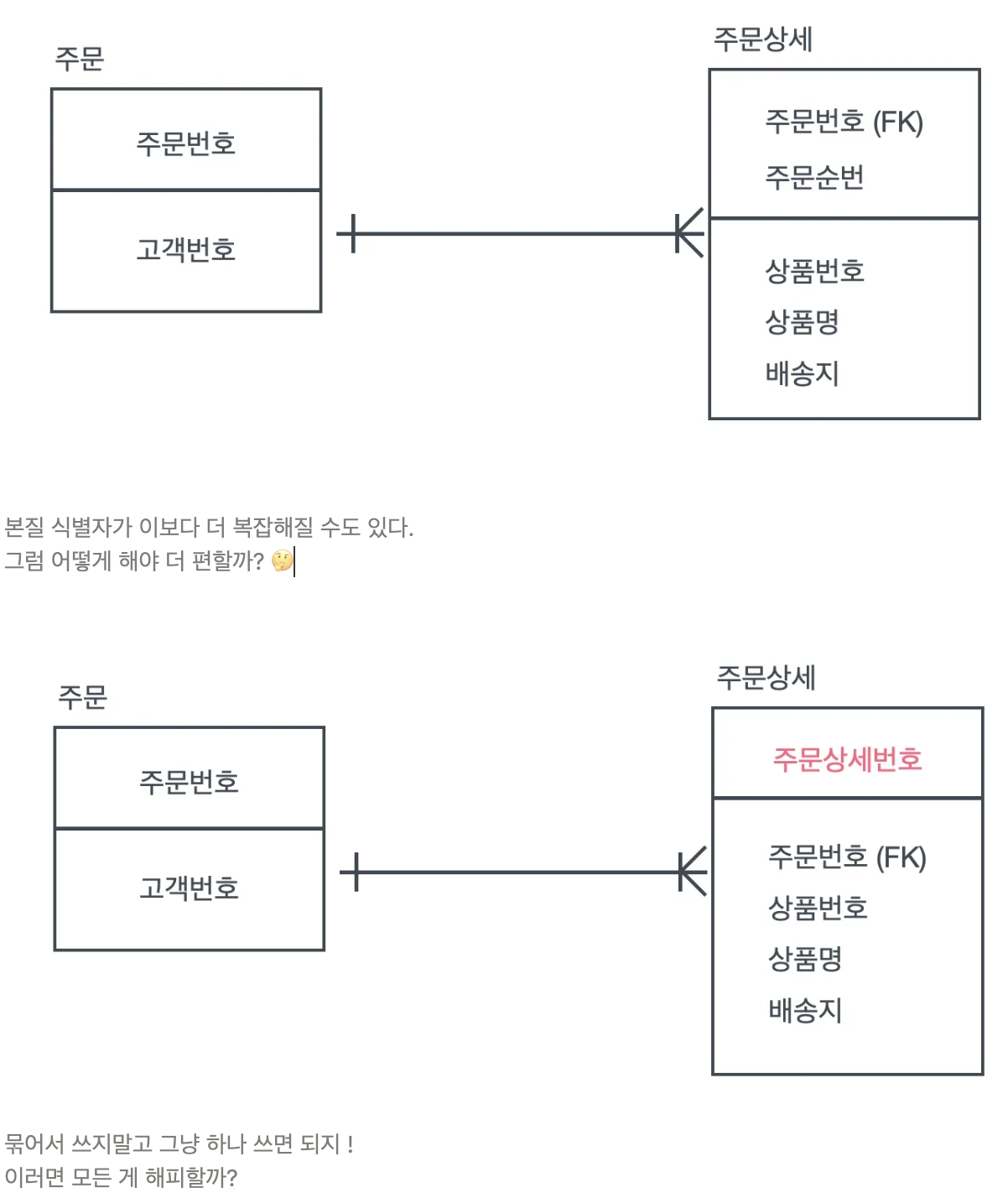
문제
-
중복데이터가 발생할 수 있다.
-
불필요한 인덱스가 발생할 수 있다.
Leave a comment